Computer Vision for real-time chess move detection
This repository implements a computer vision system to detect chess moves in real-time from a video stream. It uses deep learning models, InceptionV3 and YOLOv8, to identify chess pieces and their positions on the board, allowing for accurate move detection and analysis. The projects includes data collection, model training/fine-tuning, and real-time inference components. As part of the project a framework for generating image/FEN datasets using public available YouTube videos of chess games is included. This framework is based on a custom CNN model similar to AlexNet that extract the ground truth moves from digital chessboards in the videos and a use a robust chess move detection algorithm based on predicted logits, chess rules and the game history.
Requirements and Installation
Clone the repository:
git clone <repository-url>
cd cv-chess-detectionTo set up the environment, you need to install the required python packages. You can do this using pip:
pip install -r requirements.txtAdditionally, you need to install pycairo which is required to convert chess moves to images. You can install it using conda:
conda install -c conda-forge pycairoIn order to manage the experiments metrics and save or load trained models, Mlflow is used. Once have installed the requirements, you can run the MLflow UI with the following command:
mlflow ui --backend-store-uri file://$(pwd)/data/mlrunsThis will start a local server at http://localhost:5000 where you can track your experiments and models. you can also use the script available in the root directory and it will start the server in port 5002:
./run_mlflow.shDataset Generation from YouTube videos
The goal behind the dataset generation framework is to use publicly available YouTube videos of OTB chess games. The videos usually show the chessboard and pieces in a very sharp angle and not perfect lighting conditions, which makes the task of detecting the pieces and their positions more challenging. They also include a digital chessboard that shows the moves played in real-time, which can be used to extract the ground truth moves and positions.

Currently, there is no big publicly available dataset of OTB chess games, so this framework can be promising to follow this task which can potentially be used to train more complex and robust models for real-time chess move detection. The idea from this approach is based on the repository [1] which tries to solve the problem of generating a chess dataset from YouTube videos using a pretrained chessboard detection model applied to the digital chessboard in the videos. However the lack of options in the video extraction process reduces the applicability and the detectation of chess moves based on the existance of enough detections of the same move in the video requires processing a lot of frames to get a good accuracy.
This project provides a more flexible and modular framework to extract the chess moves from the videos using a custom trained CNN model to detect the chess pieces in the digital chessboard and implementing a more robust chess move detection algorithm based on chess rules and the game history. To achieve this, python-chess library is used to select the most likely legal moves and get the FEN representation of the chess position.
The way the detection works is by first extracting frames from the video in a given time segment, divide the chessboard in 64 squares, then using a trained AlexNet variant model predict the pieces in each square of the digital chessboard. The output of the model are the logits for each class (empty, white pieces, black pieces) for each square. From the logits, the predicted class for each square is obtained as well as the probability of each piece or empty square using a softmax function. Having the probabilities for all pieces in each square, the chess moves are detected by calculating a loss for all the resulting chessboard after applying each possible legal move from the current position and the loss of the current position assuming there is no move played. The loss is calculated based on the probabilities of the pieces in the squares and the minimum loss move is selected as the detected move. In order to avoid allucinations, a backward check is also done so if the error is to high, the last move can be reverted and chosen one of the legal moves from the previous position. This decision framework is also used in real-time chess move detection using Yolov8 or InceptionV3 models as will be explained later.
The mayor limitation in the implemented framework for dataset generation is the required manual intervention like selecting the youtube video ids, time segments for beginning and end of the game, and selecting the chessboard corners in the video frames. Future work can be done to automatize these steps as well as a selection system to avoid videos with commentary arrows, move suggestions, etc which are not valid for the dataset generation. In order to reach the desired level of automatization, some computer vision techniques can be used to detect the chessboard corners in the video frames, as well as some heuristics to select the time segments of the game based on the video duration and the presence of a digital chessboard. Handling this steps will allow to generate bigger datasets of a wider variety of chess games, chessboards, pieces, lighting conditions, angles etc. which can be used to train more robust models for real-time chess move detection.
Digital Chessboard Detection Model
The first step to train the digital chess piece detection model that is going to be used in the dataset generation framework is to create a dataset of images of chessboards with most common styles of chess pieces and color schemes. For this, a script is provided to generate synthetic images of chessboards with pieces using OpenCV, the python-chess and pycairo libraries. The script src/01_render_chess_dataset.pycreates a shynthetic dataset of chessboard images using games played in Titled Tuesday tournaments from Chess.com. The script uses public Chess.com API to get the games, check it is a standard game (not Freestyle chess which follows different rules), and then generates images of the chessboard in each step of the game.
python src/01_render_chess_dataset.pyIn order to make a model valid for most common digital chessboards and pieces, different color schemes and different piece styles are used. More color schemes and piece styles can be added modifying the constants BOARD_COLORS_LISTand CHESS_PIECES_PATHS in the script. The color schemes are based on the most common schemes avaiable in Chess.com and the pieces styles are based on the pieces from Chess.com and python-chess library (Wikipedia pieces). The pieces available at data/piece_images have been downloaded from Chess.com and Wikipedia. Finally, the generated images are saved in data/render_chess_dataset which divide the images in train, testand validation so it can be loaded and use to train the CNN model. The variety of chessboards and pieces as well as the blurring added in the processing makes the dataset more robust to train a model that can generalize well to the digital chessboards in the YouTube videos. The following images show some examples of the shynthetically generated chessboards:


Once the dataset is generated, a CNN model based on an AlexNet is trained to classify the pieces in each square of the chessboard. The model is implemented in src/02_train_chesspiece_model.py using PyTorch and is trained to classify 13 classes (“0”, “R”, “N”, “B”, “Q”, “K”, “P”, “r”, “n”, “b”, “q”, “k”, “p”) representing the empty square, white pieces (Rook, Knight, Bishop, Queen, King, Pawn) and black pieces (Rook, Knight, Bishop, Queen, King, Pawn). The model is trained for 5 epochs with a batch size of 64 and a learning rate of 0.001 using cross-entropy loss and Adam optimizer. The training process includes data augmentation techniques to improve the robustness of the model. The training process uses MLflow to track the experiments and save the best model based on the validation accuracy. After training, the model is saved in the data/models directory.
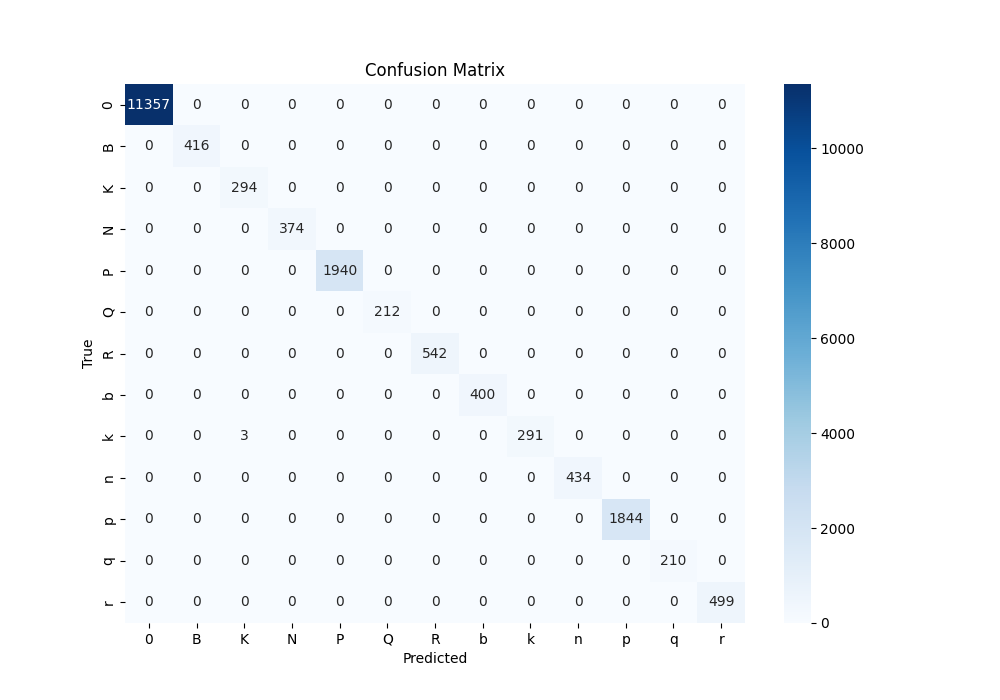
python src/02_train_render_classification_model.pyThe train metrics can be visualized running run_mlflow.sh which looks for the data/mlruns directory and start the MLflow UI in port 5002. You can then navigate to the Experiments tab and select the experiment with the name RenderChessModel to see the results of the training. To analyze the results of the training, you can also run the testing function in the src/02_train_render_classification_model.py script which loads the best model from MLflow and selected run_id and evaluates it on the test set. The testing function calculates the accuracy, precision, recall, F1-score and confusion matrix for the test set and prints the results. The confusion matrix is also plotted using seaborn library to visualize the performance of the model for each class. As can see in the confusion matrix below, the model performs perfectly for all classes and there is no confusion between any of the pieces except for 3 misclassifications between k and K. The evaluation. metrics also show a near perfect accuracy=0.9998, precision=0.9998, recall=0.9998 and F1-score=0.9998. In general, the model performs and despite possible distribution shift between the synthetic dataset and the real digital chessboards in the YouTube videos, it predicts the pieces with a high accuracy and the small errors can be handled by the chess move detection algorithm.
Dataset Generation
Once the digital chess piece detection model is trained, it can be used to generate a dataset of real chess games from YouTube videos. The script src/03_real_chess_dataset.py implements the dataset generation framework described above. The script takes as input a list of YouTube video ids and time segments for the beginning and end of the game, as well as the corners of the real chessboard and the digital chessboard in the video frames. This settings can be modified in the src/video_settings.py file where a dictionary with the video ids and settings is defined for all the videos to be processed. To facilitate the selection of the chessboard corners, a helper notebook src/03_find_corners.ipynb is provided which allows to select the corners of the chessboard in a given frame of the video using ipywidgets. The following is an example of the settings for 2 videos where video_id is the YouTube video id, gt_board_loc are the corners of the ground truth digital chessboard, irl_board_loc are the corners of the real chessboard in the video frame, time_range is the time segment for the beginning and end of the game in the format ["MM:SS:CC", "MM:SS:CC"] and step_sec is the step in seconds to extract frames from the video. In addition, an optional initial_state can be provided to set the initial position of the chessboard. If not provided, the initial position is assumed to be the standard chess starting position.
1: {
"video_id": "rrPfmSWlAPM",
"gt_board_loc": [88, 558, 764, 1233],
"irl_board_loc": [606, 911, 582, 1356],
"time_range": ["0:02:30", "6:52:00"],
"step_sec": 1,
},
9: {
"video_id": "Jvv0Dom8vkc",
"gt_board_loc": [62, 580, 726, 1243],
"irl_board_loc": [615, 1080, 582, 1339],
"time_range": ["0:00:00", "8:44:00"],
"step_sec": 0.25,
"initial_state": [
["r", "n", "b", "q", "k", "b", "n", "r"],
["p", "p", "0", "p", "p", "p", "p", "p"],
["0", "0", "0", "0", "0", "0", "0", "0"],
["0", "0", "p", "0", "0", "0", "0", "0"],
["0", "0", "0", "0", "0", "0", "0", "0"],
["0", "0", "0", "0", "0", "0", "P", "0"],
["P", "P", "P", "P", "P", "P", "0", "P"],
["R", "N", "B", "Q", "K", "B", "N", "R"],
],
},For each video the class VideoBoardExtractor is responsible to extract the frames from the video every step_sec seconds in the given time segment, crop the digital chessboard and real chessboard using the provided corners, call the predict method from GTChessboardPredicotor class to predict the move and save the corresponding images to gt, ìrl and pred folders and update the fen.csv file with the FEN representation of all the positions. On the other hand, the class GTChessboardPredictor is responsible for predicting the chess moves from the cropped digital chessboard images. Every time the predict method is called it in turn calls to the predict_gt_board method which crops the chessboard image into 64 squares and inputs as a batch to the trained chess piece detection model. The resulting logits are then used to calculate the probabilities of each piece in each square using a softmax function. The predicted chessboard position and all probabilities are returned to the predict method which then uses the robust chess move detection algorithm to detect the most likely move played based on the current position, the probabilities of each piece in each square and the game history. This logic is implemented in the get_valid_move_and_board method which decide the most likely move played based on the losses of all possible resulting positions after applying each legal move from the current position. The loss function is calculated based on the probabilities of the pieces in the squares for the chess position in question. The concrete expression for the loss function is defined in get_board_lossand is as follows:
where is the probability of the piece in square of the evaluated chess position. The current position is also evaluated assuming there is no move played and if the loss of the current position is less than the loss of the best scored move, then it is assumed that there is no move played and the current position is kept. In addition, if the loss of the best scored move is greater than a threshold, then a backward check is done to revert the last move and choose one of the legal moves from the previous position. The detected move and the minimum loss is then returned along with the new position to the VideoBoardExtractor class which render the predicted position, saves the images and updates the fen.csv file along with a min_losses.csv file which contains the losses of the best scored move.
python src/03_real_chess_dataset.pyAfter running the script, the generated dataset will be saved in data/real_chess_dataset which contains a folder for each video with the following structure:
real_chess_dataset/
video_id_1/
gt/ # Cropped images of the digital chessboard
irl/ # Cropped images of the real chessboard
pred/ # Rendered images of the predicted chess position
fen.csv # CSV file with the FEN representation of all positions
video_id_2/
...The last step is to check the quality of the generated dataset by visualizing the predicted FENs and the corresponding images. For this task, a video can be generated combining the images in gt, irl and pred folders. An easy way to validate the predicted moves for a video is to compare the last position in gtwith the last position in pred and check if they are the same. If not, then there is an error in the move detection. A common source of error is a large time_step which can cause to miss some moves. To find the step where the error occurs, the min_losses.csv file can be analyzed to find the step where the loss starts to increase significantly. This can indicate that the model is not confident about the predicted move and it is likely that an error occurred.
Real-Time Chess Move Detection
The primary goal of this project is to implement a real-time chess move detection system using deep learning models. The idea is to use a camera to capture the video stream of a chess game and then process the frames in real-time to detect the moves played. The same chess move detection algorithm used in the dataset generation framework is used here to detect the moves based on the predicted pieces in each square of the chessboard. Despite the fact that the chess move detection algorithm calculate the loss for all possible legal moves from the current position, the real-time performance is achieved by using efficient deep learning models to predict the pieces in each square of the chessboard since the move detection algorithm is very fast to compute.
However the real-time chess move detection adds another challengages compared to the dataset generation framework like detecting when a move is played or handling occlusions like the hand of the player. This problem is addressed by detecting when the image is stable based on the image difference between the current frame and previous frames and the mean color difference. This will be explained in more detail in the following sections.
To train or fine-tune the models for real-time chess move detection, a possibility is to use the generated dataset of real chess games from YouTube videos. However, since the videos are taken from a sharp angle and the chessboards are not perfectly aligned, it can be difficult even for a human to identify the pieces in each square. Therefore, a more complex model and a scaled-up dataset is required to achieve a good performance beging a current SOTA problem in computer vision. For this reason, and as a prove of concept, a dataset of top-view chess images is used to train and fine-tune the models. Even though the top-view images are less challenging than the sharp angle images, a small model like AlexNet is not able to achieve a good performance on this dataset. Therefore, two different approaches are implemented using more complex models like InceptionV3 and YOLOv8. The applications of Transfer learning allows to achieve a good performance with a relatively small dataset of around 200 images.
Top-View Dataset Preparation
A small dataset of top-view chess images is created using the same camera that is going to be used for real-time chess move detection. The process of creating the dataset consist of recording two videos that reproduce two different games. The chess games replicate the moves played by two games from the extracted YouTube videos but it can be any game. The videos are recorded with a resolution of 720p and a frame rate of 30 fps. The camera is placed above the mini chessboard to capture a top-view image of the chess pieces but is is not perfectly aligned and has a small angle due to the setup configuration. The camera quality and the lightning conditions are not optimal, which makes the task a bit more challenging. The following images shows the setup and an image example from the recorded dataset. The setup used to record the videos, where a 720p cheap webcam is used to capture the video stream and it is screwed into the stand to place it above the chessboard. As can be seen in the image, the camera is not perfectly aligned with the chessboard and there are some shadows due to the lighting conditions.


The process of creating the dataset consisted on recording a video and then extract the images for each move played by a series of timestamps. This process is done manually and can be seen looking at the notebook ssrc/03_dataset_from_video.ipynb where the timestamps for each move are listed and the code uses OpenCV to extract the frames from the video and save them in the data/recorded_datasetdirectory where the images are saved inside irlsubfolder and the file fen.csv contains the FEN representation of all the positions in the following format which is the same format used in the dataset generation framework:
,index,frame,fen
0,0,0,rnbqkbnr/pppppppp/8/8/8/8/PPPPPPPP/RNBQKBNR
1,1,2,rnbqkbnr/pppppppp/8/8/4P3/8/PPPP1PPP/RNBQKBNR
2,2,7,rnbqkbnr/pp1ppppp/8/2p5/4P3/8/PPPP1PPP/RNBQKBNR
3,3,11,rnbqkbnr/pp1ppppp/8/2p5/4P3/2N5/PPPP1PPP/R1BQKBNR
...Real-Time Chess Move Detection using InceptionV3
The first approach for real-time chess move detection uses InceptionV3 model to predict the pieces in each square of the chessboard. The model is implemented in src/05a_finetune_inception_detector.py using PyTorch and is trained to classify the same 13 classes as the simpler AlexNet CNN used for digital chessboards. The model is fine-tuned from a pretrained InceptionV3 on ImageNet-1K provided by torchvision library and based on paper [4]. Tranfer learning allows to achieve a good performance with a relatively small dataset of around 200 images by freezing the weights of the convolutional layers and only training the fully connected layers addapted to the 13 classes.
cd src
python 05a_finetune_inception_detector.pyBefore starting the training, the dataset need to be prepared for the training task. The script src/04_square_imgs_dataset.pyimplements a simple Gradio app to manually select the 4 corners of the chessboard in one image and then transform all the images in the dataset to get a square top-view image of the chessboard which will be the input to the model. The following is an example of the Gradio app where the corners of the chessboard are selected and then all the images are transformed and saved in squared directory inside the data/recorded_dataset directory.
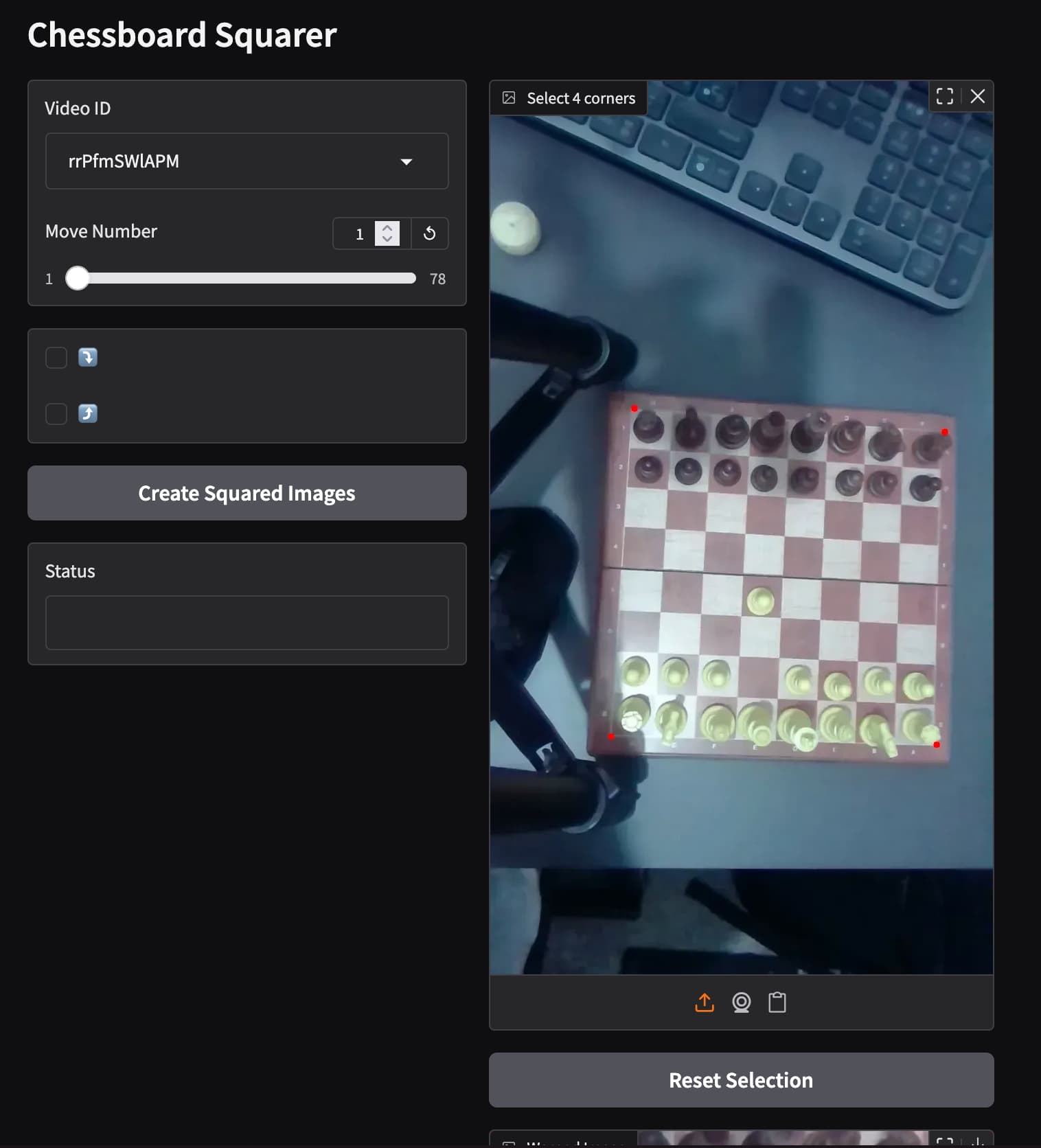
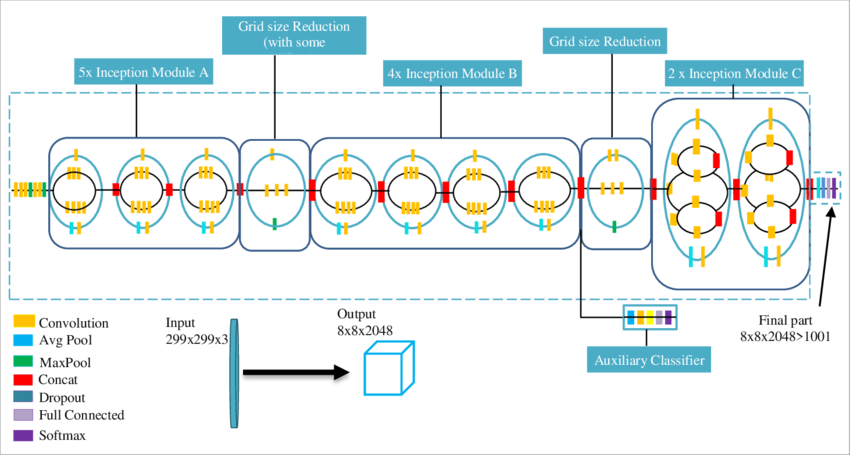
Once the dataset is prepared, the model is fine-tuned for 3 epochs with a batch size of 128 and a learning rate of 0.001 using cross-entropy loss and Adam optimizer. Since the model expects an input size of 299x299, the cropped images for each square are resized to this size before being input to the model. The training process includes data augmentation techniques to improve the robustness of the model. This includes random rotations, horizontal and vertical flips, color jittering, and random cropping expanding the dataset by 4 times. The following image shows the architecture of the InceptionV3 model used for fine-tuning where all layers up to “Mixed_7c” layer are frozen. “Mixed_7c” is one of final inception blocks just before the average pooling and fully connected layers and has 8x8 feature dimensions.
As before, the training process uses MLflow to track the experiments and save the best model based on the validation accuracy. After training, the models and metrics are saved to the data/mlruns directory and can be visualized using the MLflow UI. The script also provide a testing function to evaluate the best model on the test set and print the accuracy, precision, recall, F1-score and confusion matrix. The following table shows the evaluation metrics for all the classes and the overall accuracy, macro average and weighted average showing a good performance in general (F1 = 0.93) despite a low recall for some classes like K, N and k.
| Label | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| R | 1.00 | 1.00 | 1.00 | 5050 |
| N | 1.00 | 0.46 | 0.63 | 194 |
| B | 0.65 | 0.98 | 0.78 | 174 |
| Q | 0.76 | 0.97 | 0.85 | 222 |
| K | 1.00 | 0.29 | 0.45 | 115 |
| P | 0.63 | 0.85 | 0.72 | 118 |
| 0 | 0.96 | 0.98 | 0.97 | 935 |
| r | 0.74 | 0.65 | 0.69 | 229 |
| n | 0.57 | 0.93 | 0.70 | 148 |
| b | 0.63 | 0.91 | 0.75 | 164 |
| q | 0.83 | 0.56 | 0.67 | 106 |
| k | 0.91 | 0.30 | 0.45 | 145 |
| p | 0.96 | 0.95 | 0.95 | 899 |
| Accuracy | 0.93 | 8499 | ||
| Macro Avg | 0.82 | 0.76 | 0.74 | 8499 |
| Weighted Avg | 0.95 | 0.93 | 0.93 | 8499 |
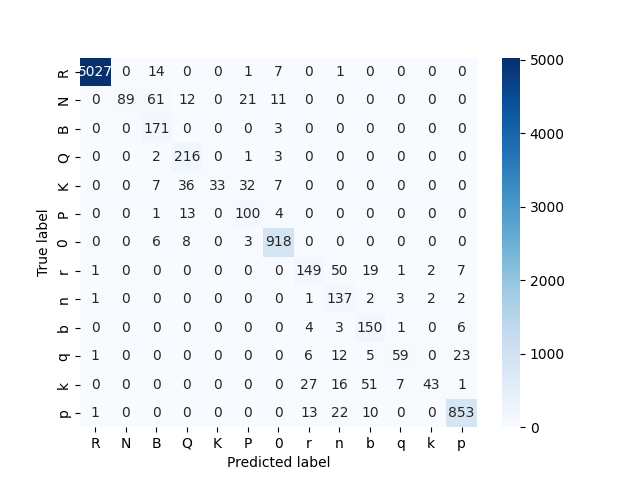
The confusion matrix for the best model and test dataset is shown below where the model performs well in most cases but some classes are confused with other like some knights with bishops or kings with bishops in some cases. This minor misclassifications can be handled by the chess move detection algorithm.
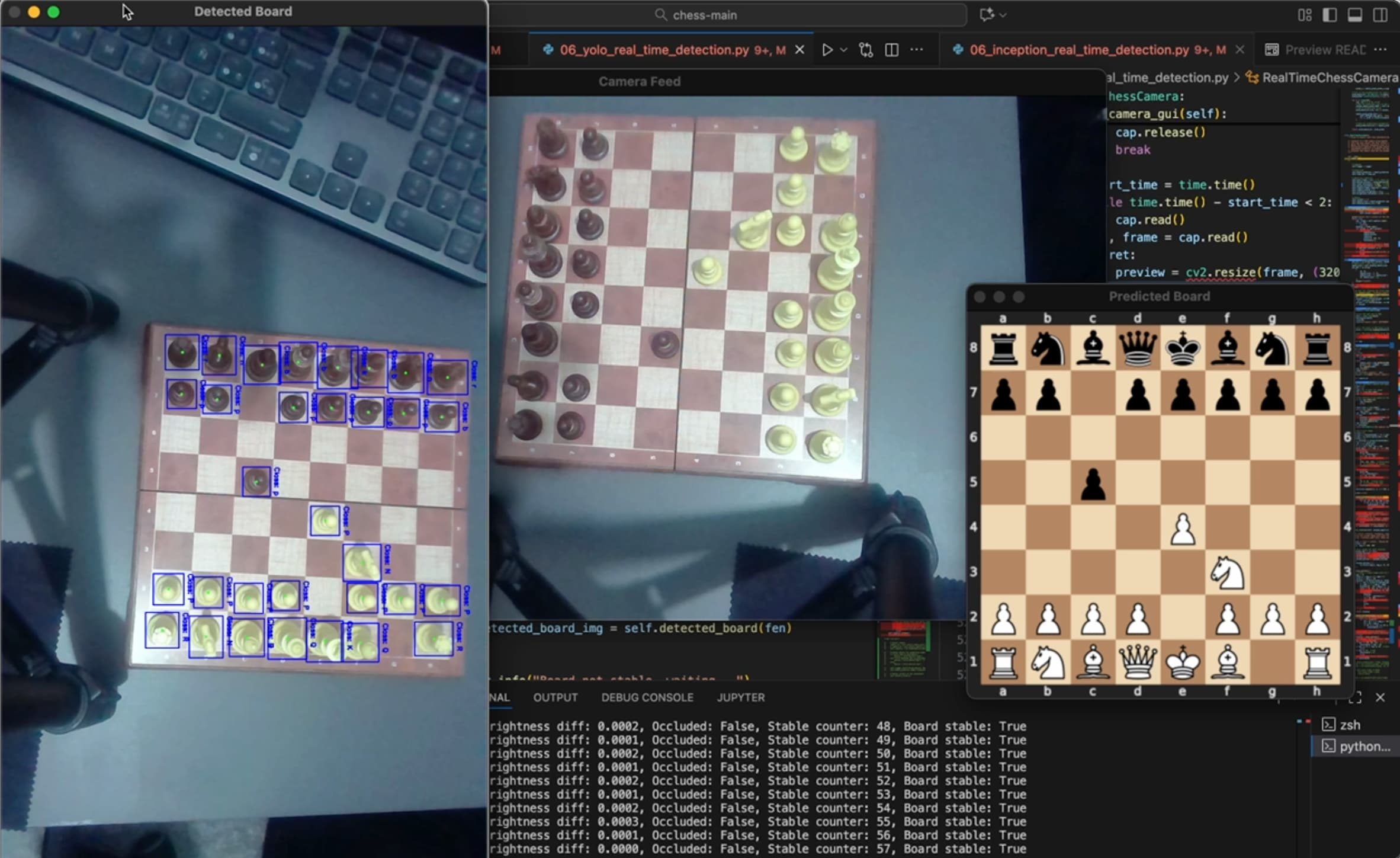
The final step after training the model is to implement the real-time chess move detection using the trained model. The script src/06_inception_real_time_detection.py implements the real-time chess move detection using OpenCV to capture the video stream from the camera and process the frames in real-time to predict the move using the trained model. It includes a class RealTimeChessCamera responsible for managing the camera feed and processing the frames, detect oclusions or movement to avoid calling the model when a player is making the move, and call the method predict from the RTChessboardPredictorclass to predict the chess moves.
As in the case of the dataset generation framework, the RTChessboardPredictor class is responsible for predicting the chess moves by cropping the chessboard image into 64 squares, inputting them as a batch to the trained InceptionV3 model, calculating the probabilities of each piece in each square using a softmax function and then using the chess move detection algorithm to detect the most likely move played based on the current position, the probabilities of each piece in each square and the game history. The detected move and the new position are then returned to the RealTimeChessCamera class which render the predicted position and display it on the screen along with the video stream from the camera.
In order to avoid false positives when there is movement or occlusions like the hand of the player, the class also includes a method is_board_stable to detect when the image is stable based on frames history. The method converts the current frame to grayscale and calculates the pixel-wise absolute difference between the current frame and the previous frame. Once the difference image is obtained, a binary threshold is applied to create a binary mask where the pixels with a difference greater than a certain threshold are set to 255 (white) and the rest to 0 (black). The number of white pixels in the binary mask is then counted as a ratio and added to a queue to keep track of the last N ratios. The mean ratio is then calculated and if it is below a certain threshold, the image is considered stable and the model can be called to predict the move. This approach allows to avoid calling the model when there is movement or occlusions in the image. However, despite detecting movement, there can still be occlusions like the hand of the player that can cover some pieces and make the prediction more difficult. To handle this, the oclussion is detected based on the mean color or brightness of the image. If the difference in brightness between the current frame and the last stable frame is greater than a certain threshold, then it is assumed that there is an occlusion and the model is not called to predict the move.
The following video shows a complete game example using the real-time chess move detection with InceptionV3 model. As can be seen in the video, the model is able to predict the moves played in real-time with a good accuracy despite the low quality of the camera, lightning conditions and constant occlusions like the hand of the player when making the move. When running the script, the available camera devices appear and after selecting the desired camera, the user needs to select the 4 corners of the chessboard in the camera frame. After this, the real-time chess move detection starts and the predicted position is displayed on the screen along with the video stream from the camera.
Real-Time Chess Move Detection using YOLOv8
The second approach for real-time chess move detection uses YOLOv8 model from Ultralytics to predict the pieces in each square of the chessboard. YOLOv8 is a state-of-the-art object detection model that can achieve high accuracy and speed. The model is implemented using the Ultralytics library which provides a simple interface to train and deploy YOLO models. The model is trained to detect the same 13 classes as the previous models using transfer learning but it also predicts the bounding boxes of the pieces in the image.
In order to train the YOLOv8 model, the dataset need to be prepared in the YOLO format. To do this, the Roboflow platform is used to facilitate the annotation and export process. The images in data/recorded_dataset/video_id/irl are uploaded to Roboflow and then annotated using the Roboflow annotation tool. The annotations are done by drawing bounding boxes around each piece in the image and assigning the corresponding class label. Once the images are annotated, they are split into training, validation and test sets and then exported in YOLOv8 format. The exported dataset is then downloaded and unzipped in data/roboflow_chess_dataset directory.
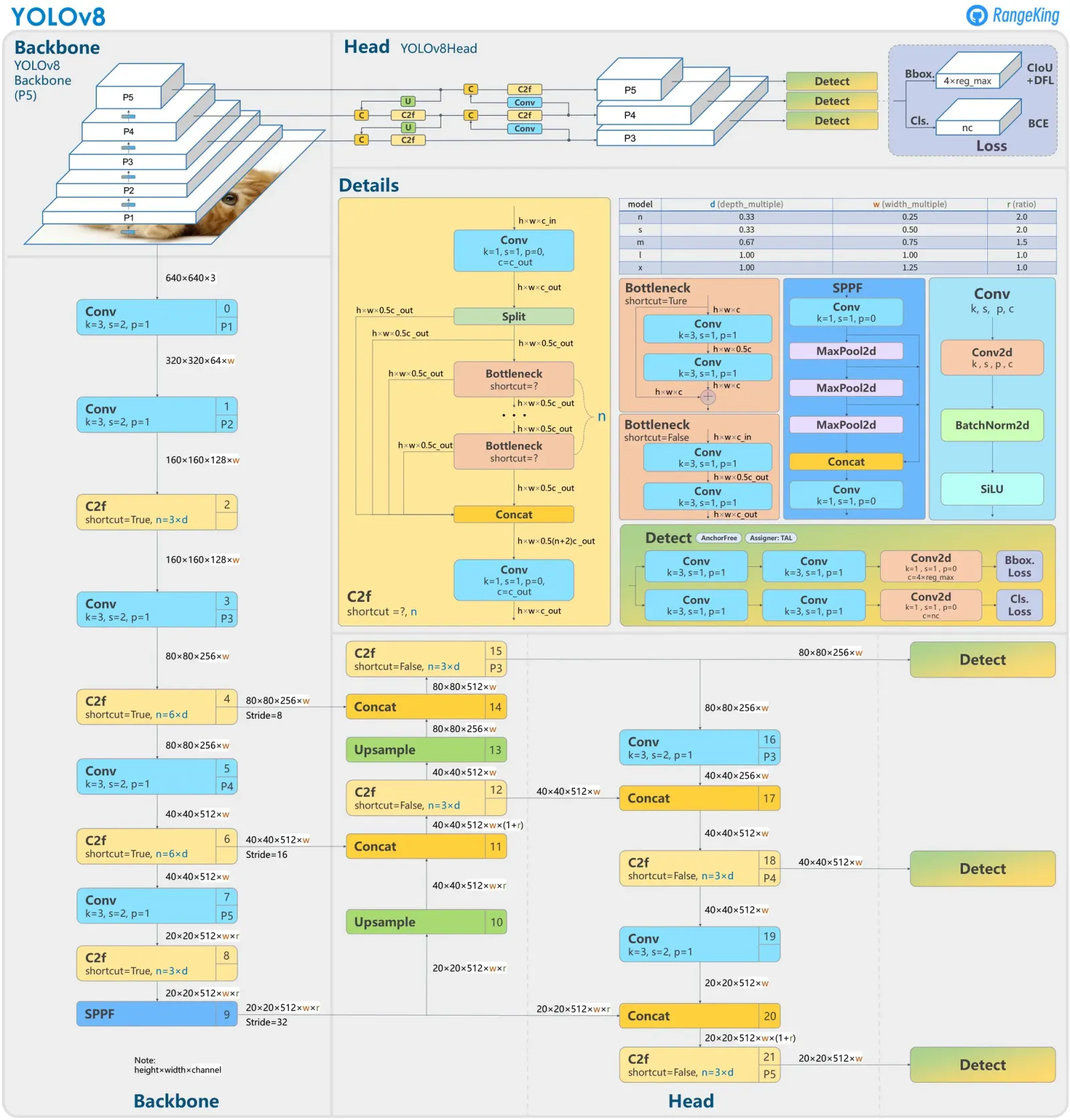
Once the dataset is prepared, the YOLOv8 model was trained in Colab using a T4 GPU for 100 epochs. Among the YOLOv8 models available, YOLOv8m (medium) was used as base model which is a good compromise between accuracy and speed. YOLOv8 is a very powerful but also complex model as can be seen in the architecture diagram below. The model architecture is divided in three main parts: Backbone, Neck and Head where the backbone is responsible for extracting features from the input image, the neck is responsible for aggregating the features from different layers and the head is responsible for predicting the bounding boxes and class labels. This parts can also be decomposed in more specific modules colled Convolutional, C2F, Bottleneck, SPPF and Detect blocks. As can be seen in the diagram, the Convolutional block consist on a 2D convoltional laey follow by a batch normalization and a SiLU activation function. The C2F block on the other hand consist on a series of convolutional layers with residual connections and concatenations and the Bottleneck are a sequence of convolutional blocks with a shortcut connection similar to ResNet if shortcut=True. Finally, the SPPF block is a spatial pyramid pooling layer that concatenates the outputs of multiple max-pooling layers with different kernel sizes to capture features at different scales and the Detect block is responsible for predicting the bounding boxes and class labels using anchor boxes and a series of convolutional layers. Unlike previous YOLO versions, YOLOv8 uses anchor-free detection which simplifies the model and improves the performance. More details about the architecture and the modules can be found in [8] and [9].
The training process includes data augmentation techniques to improve the robustness of the model and have enough data to achieve a good performance. This includes random 90º rotations, flips and scale jittering. The following images shows the training graphs, data distribution and confusion matrix:
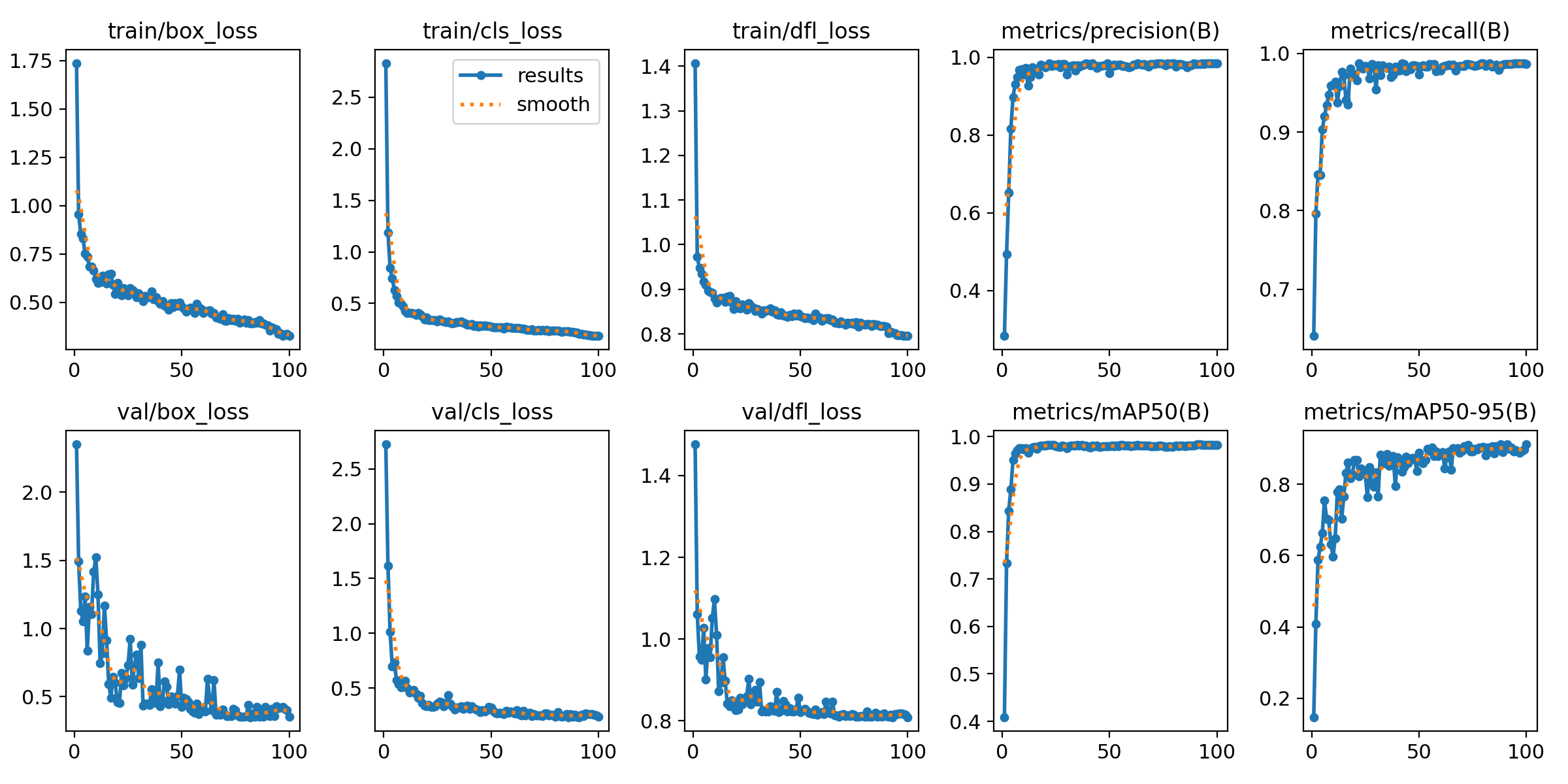
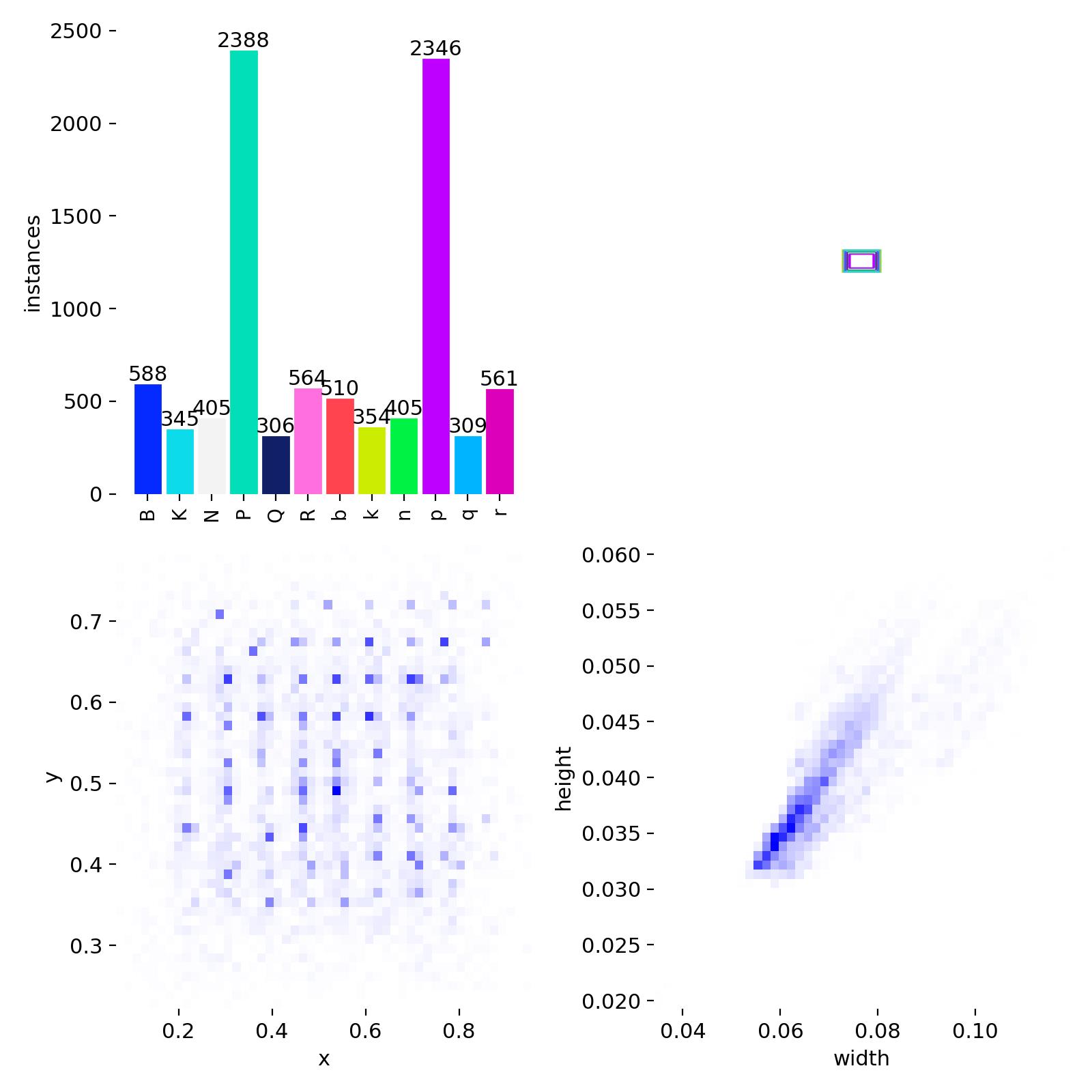
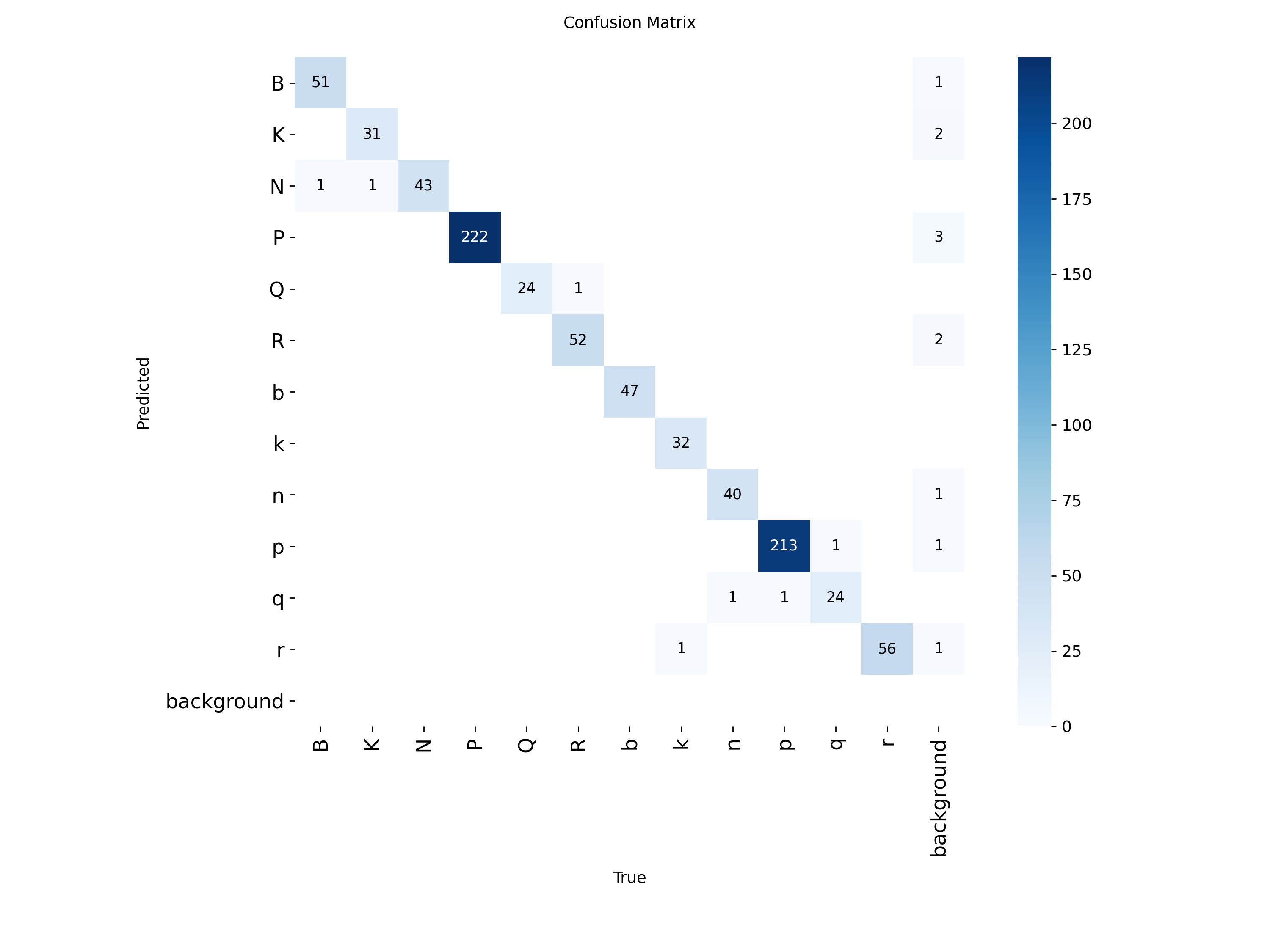
The data distribution shows some inbalance between the classes since there are many more paws (P, p) that the other pieces while the rest of the pieces have a similar number of instances. This a common problem in a chess game since there are 8 pawns per side at start in every normal game. On the other hand, the training metrics show a good performance of the model during training and validation with a good convergence and no overfitting despite some fluctuations in validation loss. The final training [email protected] and mAP@95 are 0.982 and 0.911 respectively while the validation [email protected] and mAP@95 are 0.982 and 0.916 respectively which indicates a good generalization of the model. Finally, the confusion matrix shows a great performance of the model in general with some ocassional individual misclassifications between some pieces.
The advantage of using YOLOv8 in comparison of a normal CNN classifier like InceptionV3 is that it can be used to detect the pieces in the whole chessboard image instead of cropping each square and predicting the piece in each square. This can potentially improve the accuracy of the model since the crops can lose some information and context of the pieces. This is a problem that amplifies with the camera angle and the non-perfect alignment of the chessboard. Using this approach, the model can learn to detect the pieces in the context of the whole chessboard and not only in the context of each square. However, this approach requires an additional step to map the detected bounding boxes to the corresponding squares of the chessboard.
cd src
python 05b_finetune_yolo_detector.pyThe results of the YOLOv8 model are the bounding boxes of the detected pieces along with the class and confidence score. As in the previous approach a perspective transformation is calculated using OpenCV when selecting the corners of the chessboard in the OpenCV window launched by src/06_yolo_real_time_detection.py script for real time detection. The match between the bounding boxes and the squares is done by calculating the center of each bounding box and the center of each square in the chessboard. The center of each square can be easily calculated in the transformed square chessboard space asumming all squares have the sime size. The next step consist of applying the inverse perspective transformation to get the center of each square in the original image and finally assign each detection to the square with the closest center using Hungarian algorithm from scipy.optimize.linear_sum_assignment function.
cd src
python 06_yolo_real_time_detection.pyOnce the pieces are assigned to the squares, the probabilities of each piece in each square need to be calculated based on the confidence scores of the detections. The proper detection is made by the class RTChessboardPredictor which is identical to the one used in the InceptionV3 approach except for the predict_gt_board method which is modified to use the YOLOv8 model to detect the pieces in the whole chessboard image and then map the detections to the squares using the method described above. Here the probabilities are calculated based on the confidence scores of the detections. If a square has a detection assigned, then the probability of the detected piece is set to the confidence score and the probabilities of the other pieces are set to a small value (1 - confidence score) / 12. If a square does not have any detection assigned, then the probability of empty class is set to 1 and the probabilities of the other pieces are set to 0.
Above the chess move detection class is the RealTimeChessCamera class which is also identical to the one used in the InceptionV3 approach. It is responsible for managing the camera feed and processing the frames, detect oclusions or movement to avoid calling the model when a player is making the move, and call the method predict from the RTChessboardPredictorclass to predict the chess moves. The following video shows a complete game example using the real-time chess move detection with YOLOv8 model. As can be seen in the video, the model is able to predict the moves played in real-time with a good accuracy despite the low quality of the camera and constant occlusions by the hand of the player when making the move.
When running the script, the available camera devices appear and after selecting the desired camera, the user needs to select the 4 corners of the chessboard in the camera frame. After this, the real-time chess move detection starts and the predicted position is displayed on the screen along with the video stream from the camera and the detected bounding boxes of the pieces in the chessboard image. The result is a complete real-time chess move detection despite some misclassifications betweeen queen and bishop in some cases.
Acknowledgements
- [1] Rob Mulla, https://github.com/RobMulla/chessboard-vision, 2022.
- [2] Simon J.D. Prince, “Understanding Deep Learning”, 2023.
- [3] Laurence Moroney, “AI and ML for Coders in PyTorch”, 2025.
- [4] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew Wojna, “Rethinking the Inception Architecture for Computer Vision”, 2015.
- [5] Maciej A. Czyzewski, Artur Laskowski, Szymon Wasik, “Chessboard and Chess Piece Recognition With the Support of Neural Networks”, 2020.
- [6] David Mallasén Quintana, Alberto Antonio del Barrio García, Manuel Prieto Matías, “LiveChess2FEN: a Framework for Classifying Chess Pieces based on CNNs”, 2020.
- [7] James Gallagher, “Roboflow: Represent Chess Boards Digitally with Computer Vision”, 2023.
- [8] Jacob Solawetz, Francesco, https://blog.roboflow.com/what-is-yolov8/, 2024.
- [9] Dr. Priyanto Hidayatullah, https://www.youtube.com/watch?v=HQXhDO7COj8, 2023.
- [10] Think Autonomous, https://www.thinkautonomous.ai/blog/hungarian-algorithm/, 2023.